
Enterprise Software Development Trends in USA 2026
Over the last few years, I’ve noticed a pattern across startup teams and mid-sized SaaS products in the USA, UK, Germany, Australia, and Canada. Teams are building increasingly complex systems long before their products actually require that level of sophistication.
A lot of this comes from chasing enterprise software development trends too early. Teams adopt distributed infrastructure, aggressive automation, heavy orchestration layers, and multi-service deployment pipelines before they even achieve product stability.
On paper, these decisions sound modern. Scalability, cloud-enabled workflows, interoperability, virtualization, resilience, and real-time analytics all sound like smart architectural goals. But in practice, small engineering teams often create more operational friction than actual business value.
I’ve worked with remote developers maintaining SaaS products where deployment workflows became harder to manage than the product itself. The architecture looked impressive in diagrams, but maintainability, efficiency, and responsiveness suffered badly under real production pressure.
In 2026, one of the biggest shifts in enterprise software development is not about adding more complexity. For growing companies, custom software development solutions for enterprises help reduce unnecessary architectural weight while improving reliability, governance, performance, and long-term adaptability.

Why This Problem Happens in Real Teams
Most engineering bottlenecks do not begin with bad developers. They usually begin with pressure.
Startup teams operate with tight timelines, evolving product requirements, and limited engineering resources. Product teams are expected to deliver innovation quickly while simultaneously preparing backend systems for future scaling assumptions that may never happen.
That creates predictable behavior.
Teams start optimizing too early for:
- Massive deployment scalability
- Enterprise-grade orchestration
- Multi-cloud infrastructure
- Advanced synchronization layers
- Deep analytics pipelines
- Distributed workflow systems
The intention is usually good. Founders want modernization. Developers want clean architecture. Product teams want flexibility and future-proof infrastructure.
But small engineering teams rarely have enough operational maturity to support highly distributed systems properly.
I’ve seen SaaS products introduce:
- Event-driven infrastructure before achieving product-market fit
- Excessive API abstraction layers
- Premature decentralization
- Complex encryption policies that slowed development velocity
- Heavy monitoring stacks nobody maintained
- Centralization strategies replaced too early with fragmented services
The result is usually reduced productivity instead of optimization.
Ironically, teams pursuing agility often lose adaptability because every change now affects multiple interconnected services.
In remote development teams, collaboration also becomes harder when architecture complexity outpaces documentation discipline.

Where Most Teams Make the Wrong Decision
One of the biggest mistakes I see in enterprise software development trends across the USA in 2026 is copying enterprise patterns without enterprise-level engineering capacity. This is where choosing an enterprise software development company in the USA becomes important, because the right partner should build around real scale, not just trend-driven architecture.
A lot of online advice assumes:
- Large DevOps teams
- Dedicated platform engineers
- Full-time SRE ownership
- Mature compliance processes
- Stable product requirements
Small SaaS teams rarely have these advantages.
I’ve seen startups introduce microservices far too early because they believed monoliths were outdated. In reality, their actual problem was poor maintainability and unclear ownership, not architecture limitations.
Most small teams underestimate how much operational overhead comes with:
- Infrastructure orchestration
- Service compatibility management
- Deployment synchronization
- Monitoring maintenance
- Security governance
- Cross-service integration testing
This becomes especially painful in remote engineering teams.
When developers work across multiple time zones, debugging distributed deployment failures becomes extremely expensive. One broken integration can slow entire workflow pipelines.
Tool Obsession Creates More Complexity
Teams constantly chase:
- AI-driven automation
- Hyper-customization
- Advanced virtualization
- Excessive cloud optimization
- Real-time data streaming
- Highly personalized user infrastructure
But many products simply do not require that level of sophistication.
I’ve worked on SaaS products where a simpler centralized architecture outperformed highly fragmented systems because:
- Deployment was easier
- Monitoring was cleaner
- Collaboration improved
- Technical debt stayed manageable
- Product iteration remained fast
Enterprise software development trends in 2026 increasingly reward stability and operational clarity over architectural hype.
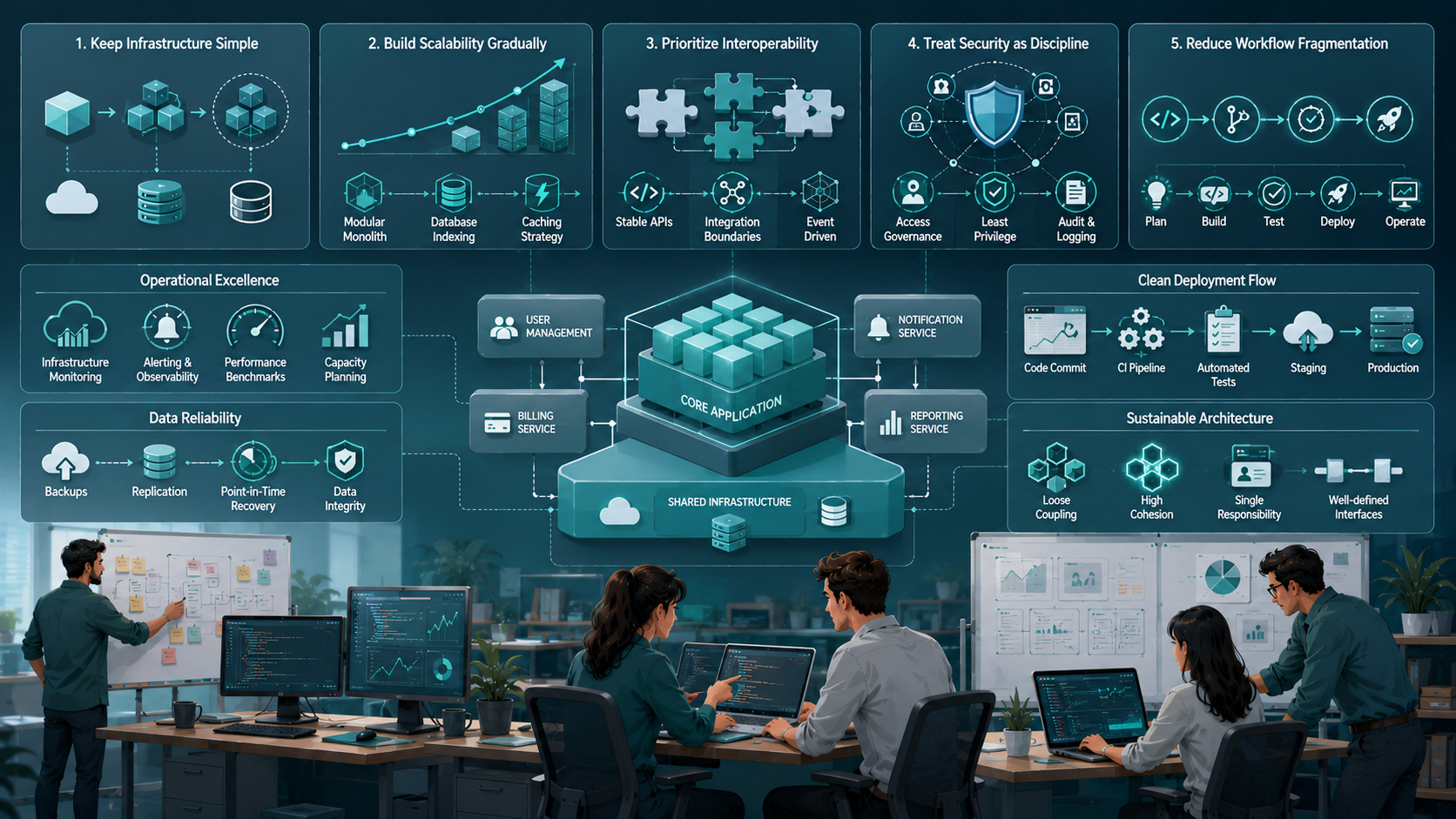
Practical Fixes That Actually Work
The most sustainable engineering improvements are usually boring.
Not simplistic — just operationally realistic.
1. Keep Infrastructure Simple Until Scaling Is Proven
Small teams should optimize for maintainability first.
That means:
- Fewer services
- Cleaner deployment workflows
- Shared infrastructure ownership
- Reduced synchronization dependencies
- Simpler architecture diagrams
In one SaaS product I worked on, consolidating six backend services into a modular monolith improved:
- Reliability
- Deployment efficiency
- Monitoring visibility
- Team productivity
Performance actually improved because unnecessary network complexity disappeared.
2. Build Scalability Gradually
Real scalability comes from identifying bottlenecks accurately.
Most systems fail because of:
- Poor database indexing
- Weak caching strategies
- Unoptimized queries
- Excessive API calls
- Inefficient analytics processing
Not because they lack Kubernetes clusters or distributed orchestration.
Before Introducing New Infrastructure
- Measure actual load
- Benchmark performance
- Validate resource usage
- Understand operational trade-offs
Optimization without measurement creates technical debt very quickly.
3. Prioritize Interoperability Over Tool Quantity
Many engineering teams confuse modernization with adding more platforms.
A better approach is improving compatibility between existing systems.
Focus Areas
- Stable APIs
- Predictable deployment behavior
- Shared documentation
- Clear integration boundaries
- Consistent architecture standards
This improves adaptability and reduces long-term maintenance overhead.
4. Treat Security as Operational Discipline
Security is not just encryption.
Strong enterprise security usually depends on:
- Access governance
- Deployment standardization
- Infrastructure monitoring
- Clear compliance ownership
- Reliable backup workflows
I’ve seen products with advanced encryption still fail audits because documentation and operational transparency were poor.
Simple operational discipline scales better than overly complicated security infrastructure.
5. Reduce Workflow Fragmentation
One of the biggest productivity killers in remote teams is fragmented workflow management.
Too many platforms create:
- Communication delays
- Monitoring blind spots
- Integration instability
- Collaboration friction
Streamlining engineering workflows often improves velocity more than introducing new automation layers.
Sometimes removing tools improves efficiency more than adding them.

When This Approach Fails
Simpler architecture does have limitations.
At larger scale, centralized systems eventually struggle with:
- Massive concurrency
- Global deployment distribution
- Advanced analytics workloads
- High-volume synchronization
- Complex personalization engines
Large enterprise platforms with thousands of daily transactions often require:
- Distributed infrastructure
- Service segmentation
- Advanced orchestration
- Independent deployment pipelines
- Dedicated resilience engineering
This is where decentralization becomes necessary.
But most startup teams reach for those patterns years too early.
Industries Where Complexity Is Unavoidable
Another limitation appears in heavily regulated industries where compliance requirements force stricter governance and infrastructure separation.
In those environments:
- Monitoring complexity increases
- Security workflows expand
- Documentation requirements grow
- Operational overhead becomes unavoidable
The key is timing.
Complexity should emerge from real operational pressure — not trend-driven assumptions.

Sustainable Practices for Small Engineering Teams
The healthiest engineering teams I’ve worked with shared similar habits.
Not necessarily the most advanced stacks. Just cleaner operational discipline.
Focus on Architecture Stability
Avoid rewriting infrastructure every six months.
Constant transformation destroys maintainability and slows product momentum.
Stable systems improve:
- Reliability
- Productivity
- Team onboarding
- Collaboration
- Deployment consistency
Improve Documentation Discipline
Most scaling problems become worse because system behavior exists only inside developers’ heads.
Good documentation improves:
- Transparency
- Governance
- Integration consistency
- Deployment safety
- Cross-team collaboration
Especially in remote engineering teams.
Reduce Technical Debt Continuously
Technical debt becomes dangerous when ignored for too long.
Small improvements matter:
- Refactoring duplicated logic
- Simplifying APIs
- Improving monitoring coverage
- Standardizing deployment workflows
- Cleaning infrastructure configuration
Consistency creates long-term efficiency.
Optimize for Developer Responsiveness
Fast engineering teams usually have:
- Short deployment cycles
- Clear ownership
- Minimal operational friction
- Predictable infrastructure
- Strong observability
Responsiveness matters more than architectural sophistication in early-stage SaaS products.
Avoid Burnout Through Simpler Systems
Overengineered systems create operational fatigue.
When every deployment requires:
- Multiple approvals
- Cross-service coordination
- Complex monitoring checks
- Infrastructure troubleshooting
Teams lose momentum quickly.
Sustainable software development depends heavily on reducing cognitive load.
Conclusion
One of the biggest enterprise software development trends in USA 2026 is the growing realization that simpler systems often outperform overengineered architectures in small and mid-sized engineering teams.
Scalability, automation, interoperability, analytics, cloud-enabled infrastructure, and orchestration all matter. But introducing them too early creates operational instability instead of long-term resilience.
The biggest mistake most startup teams make is optimizing for hypothetical scale instead of solving current engineering bottlenecks clearly.
Good architecture is rarely about chasing trends.
It’s usually about building systems your team can realistically maintain, monitor, deploy, secure, and evolve without slowing product development.
Sustainable engineering comes from balancing innovation with operational simplicity.
FAQ
Usually not in the early stages. Most startups benefit more from simpler centralized systems with strong maintainability and cleaner deployment workflows.
Rapid feature delivery, limited engineering resources, and weak documentation processes often create long-term maintainability issues.
Only if operational complexity genuinely requires it. Most small teams underestimate the monitoring and orchestration overhead involved.
Clear documentation, standardized deployment workflows, better monitoring, and simpler infrastructure reduce operational errors significantly.
Stability. Reliable systems with predictable performance and cleaner workflows usually scale better over time than overly optimized architectures.
Reference
Written by

Paras Dabhi
VerifiedFull-Stack Developer (Python/Django, React, Node.js)
I build scalable web apps and SaaS products with Django REST, React/Next.js, and Node.js — clean architecture, performance, and production-ready delivery.
LinkedIn

