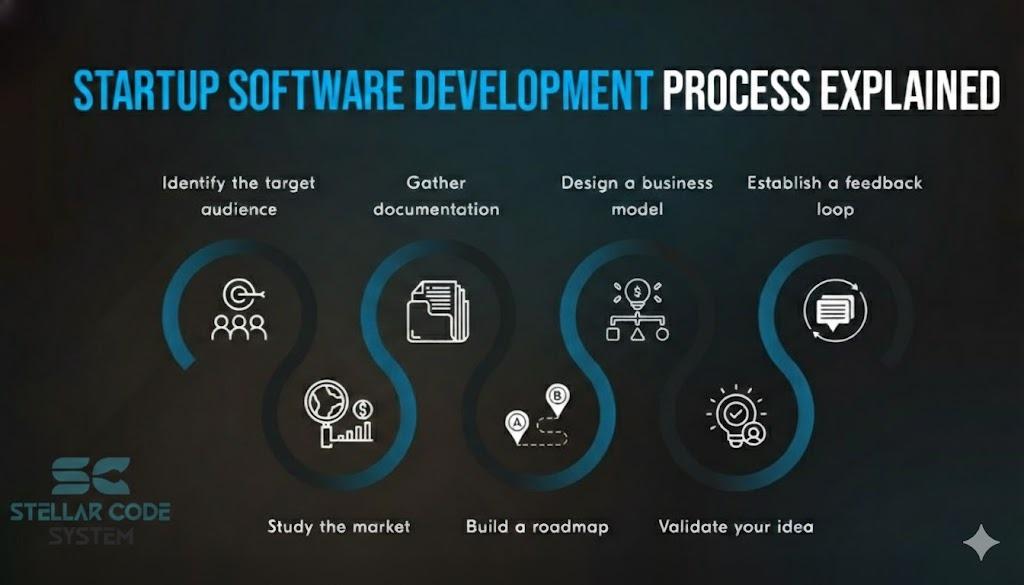
Startup Software Development Process Explained for Early-Stage Founders
I’ve seen this pattern too many times. The MVP ships. Everyone celebrates. A few real users sign up. Then suddenly, every new feature feels slower to build, bugs multiply, and releases become stressful.
The team starts asking: “Why did development slow down after launch?”
The process didn’t change — but everything feels harder.
Here’s what actually happens in real startup projects.
Why this problem actually happens

The short version: the MVP was built for speed, not stability — and now you’re building on top of it.
Constant scope changes
In early-stage startups, priorities shift fast — often weekly. New ideas, investor feedback, or early user requests keep altering the roadmap.
When scope keeps changing mid-sprint, developers lose execution focus. Features stay half-finished, technical debt increases, and the team feels busy but unproductive.
In early-stage startups, product direction evolves weekly. That’s normal. But after launch, instead of stabilizing, many teams continue changing priorities mid-sprint. What was temporary becomes permanent chaos.
When scope shifts constantly, no architecture has time to settle.
Lack of ownership
In small startup teams, responsibilities often overlap. Everyone contributes, but no one truly owns architecture, release quality, or long-term stability.
Without clear ownership, decisions become reactive. Problems linger, technical debt grows silently, and accountability gets blurred when things break.
In small teams, everyone does everything.
That sounds efficient, but it creates hidden gaps:
- No one owns system design.
- No one owns release quality.
- No one owns long-term maintainability.
Without ownership, decisions are made for today, not for six months from now.
Budget pressure
Startups operate under tight runway constraints, so every sprint feels tied to survival. That pressure pushes teams to prioritize speed over maintainability.
Refactoring gets postponed, tests are skipped, and “we’ll fix it later” becomes normal. Over time, those shortcuts slow development far more than they saved.
Startups are always managing the runway.
So refactoring gets postponed.
Tests get skipped.
“Cleanup sprint” never happens.
Those shortcuts don’t disappear. They compound.
Founder-driven urgency
Founders naturally push for speed — demos, investor updates, customer requests. That urgency often flows directly into the dev team.
When every feature feels “critical,” developers rush decisions, skip proper review, and merge unstable code. Short-term momentum increases, but long-term stability suffers.
Founders move fast — and they should. But when urgency overrides execution discipline, teams start merging half-finished features, bypassing review, or deploying under pressure.
That works once or twice. Not for a year.
MVP shortcuts become permanent architecture
MVPs are built to validate ideas quickly, so shortcuts are expected — hardcoded logic, minimal validation, limited tests.
The problem starts when that temporary structure becomes the foundation of the real product. What was meant to last three months ends up supporting real customers, making every new feature harder and riskier to build.
The biggest issue?
MVP code is rarely rewritten.
I’ve worked on products where:
- Hardcoded pricing logic stayed for 18 months.
- Auth systems built in a week powered enterprise clients.
- Database schemas designed for 50 users handled 10,000.
The startup software development process didn’t break after MVP.
It was fragile from day one.
Where most startups or developers get this wrong

This is where I’ve seen teams repeat the same mistakes.
Copying processes from larger companies
Early-stage startups often try to replicate processes used by big tech companies — full Scrum ceremonies, complex planning cycles, heavy documentation.
But small teams don’t have the same scale or stability.
What works for 200 engineers can slow down a team of five, adding overhead without solving core execution problems.
In most early-stage startups, someone says, “Let’s implement full Scrum.”
So suddenly:
- Long sprint planning sessions
- Detailed story points
- Multiple ceremonies
But with a 4-person team, this adds overhead without solving the core problem.
Process cannot compensate for unclear priorities.
Over-engineering too early
Some startups try to design for scale before they’ve validated the product.
They introduce complex architectures, abstractions, or services that aren’t needed yet.
This slows development, increases maintenance effort, and adds cognitive load to a small team — all before real user demand justifies it.
I’ve seen teams introduce:
- Microservices at 100 users
- Complex permission systems before real customers
- Heavy CI pipelines that slow iteration
They optimize for scale before they validate product-market fit.
That’s backwards.
Confusing speed with chaos
Moving fast doesn’t mean changing direction daily or merging unfinished work.
That’s not speed — it’s instability.
When priorities shift constantly and standards drop, teams feel busy but progress slows.
Real speed comes from focused execution, not constant reaction.
Speed is not:
- Changing direction every two days
- Pushing unfinished features
- Skipping reviews
That’s instability.
Real speed comes from predictable execution.
Ignoring refactoring
In many startups, refactoring is seen as optional — something to do “after we grow.” So messy code stays messy.
Over time, every new feature takes longer to build because developers are afraid to touch fragile areas.
Small cleanup early prevents major slowdowns later.
In most startups, refactoring is treated as optional.
“I’ve seen teams do this…”
They stack feature after feature on messy foundations, hoping they’ll rewrite later.
They rarely do.
No feedback loop integration
After MVP, real users start interacting with the product — but many teams don’t systematically capture and use that feedback.
Without structured tracking of user issues, feature adoption, and behavior data, development decisions become guesswork.
The team keeps shipping features without knowing what actually improves the product.
After MVP, real user feedback starts coming in.
But many teams don’t structure it:
- No tracking of recurring issues
- No measuring feature adoption
- No linking support issues to sprint planning
So they build blindly.
Practical solutions that work in real projects

You don’t need more engineers.
You need tighter execution boundaries.
Here’s what has worked consistently in small teams I’ve been part of.
1. Lock 2-week execution cycles
Define a clear 2-week scope and protect it.
No new features mid-cycle — only critical fixes.
This creates predictable output and reduces context switching.
You may delay some ideas, but you gain stability and consistent delivery.
Even if product direction changes, execution cycles shouldn’t.
- Define scope for 2 weeks.
- No adding features mid-cycle.
- Only critical bugs allowed in.
Trade-off:
You delay some ideas.
But you gain predictable output.
2. Assign technical ownership clearly
In a small team, clarity matters more than hierarchy.
Assign one person to own architecture decisions, one to guard release quality, and one to oversee infrastructure reliability — even if they also code daily.
When ownership is clear, decisions move faster, accountability improves, and problems don’t float around unresolved.
In a 5-person team:
- One person owns architecture decisions.
- One person owns the release quality.
- One person owns infrastructure reliability.
Ownership doesn’t mean hierarchy.
It means clarity.
When something breaks, everyone knows who decides.
3. Refactor 10–15% every sprint
Reserve a small portion of each sprint for cleanup in the areas you’re already touching.
Rename unclear code, remove dead logic, simplify complex functions, and add minimal tests around risky paths.
Small, continuous improvements prevent the need for risky full rewrites later.
Not a “rewrite everything” plan.
Just:
- Clean touched modules.
- Remove dead code.
- Improve naming and structure.
- Add minimal tests around risky areas.
Small, continuous cleanup prevents big disasters.
4. Separate experimentation from core flows
Keep experimental features isolated from critical systems like authentication, payments, or primary user workflows.
Use feature flags or separate modules so experiments can be added or removed safely.
This prevents temporary ideas from destabilizing the foundation of your product.
Use feature flags or isolated modules.
Keep:
- Authentication
- Payments
- Core workflows
Stable.
Experiments should not pollute foundational logic.
5. Add lightweight documentation
You don’t need long documents — just clarity where it matters.
Maintain a simple architecture diagram, basic API notes, and a clear deployment checklist.
This prevents knowledge from living in one developer’s head and reduces onboarding and debugging time later.
Not long documents.
Just:
- Simple architecture diagram
- Deployment checklist
- API contract summary
This reduces onboarding friction and prevents tribal knowledge.
6. Measure outcomes, not just features shipped
Shipping features feels productive, but it doesn’t guarantee progress.
Track whether new features are actually used, reduce support issues, or improve retention.
If output increases but outcomes don’t improve, your process is busy — not effective.
Track:
- Feature adoption
- Retention shifts
- Support ticket frequency
If you’re shipping features that increase support load, your process is not improving.
When this approach does NOT work

This lean structure isn’t universal.
Regulated industries
In fintech, healthcare, or compliance-heavy domains, lightweight processes aren’t enough.
You need strict documentation, audit trails, security reviews, and controlled releases.
Moving fast without formal structure in these environments creates legal and operational risk that small shortcuts can’t afford.
Fintech, healthcare, and compliance-heavy domains require stricter documentation and process control. Lightweight execution alone won’t be enough.
Large distributed teams
Once your team grows across multiple time zones, informal communication stops working.
Quick decisions in Slack or hallway conversations no longer scale.
Without stronger coordination, documentation, and structured planning, misunderstandings increase and delivery slows down — even if everyone is working hard.
Once you cross 12–15 engineers across time zones, informal coordination fails.
You’ll need stronger coordination layers.
Hardware-heavy or deep-tech startups
When your product depends on hardware integration, firmware, or complex R&D, iteration cycles are naturally slower.
You can’t just push updates instantly like pure software products.
Testing takes longer, dependencies are tighter, and experiments are costlier.
In these cases, lightweight startup processes need more planning discipline and longer validation cycles.
If your development involves hardware integration or heavy R&D, iteration cycles are naturally slower. Two-week execution locks may be unrealistic.
Teams without a technical leader
When no one owns technical direction, decisions become fragmented.
Architecture evolves based on whoever is working on a feature at the moment.
Without a technical leader to define standards and long-term structure, the codebase drifts, inconsistencies grow, and fixing systemic issues becomes harder over time.
If no one can guide architecture decisions, replaceable design becomes guesswork. Process cannot fix lack of technical judgment.
Best practices for small startup teams

These are habits that keep teams sustainable long term.
Keep architecture replaceable
Assume parts of your system will change — because they will. Avoid tightly coupling modules or building deep dependencies that make one change ripple everywhere.
If a component becomes painful to modify or swap, that’s a warning sign. Replaceable architecture gives small teams flexibility without full rewrites.
Assume parts of your system will change. Avoid deep, tangled dependencies.
Freeze scope during execution
Once a sprint or execution cycle starts, protect it. Don’t inject new features or shifting priorities unless something is truly critical.
Constant scope changes break focus, create half-finished work, and reduce delivery predictability. Stability during execution is what actually improves speed over time.
Changing direction every week destroys momentum. Protect sprint focus.
Make technical debt visible
Don’t let shortcuts and temporary fixes hide in the code. Maintain a visible list of technical debt items so the team knows what needs attention.
When debt is tracked openly, it can be prioritized, planned, and addressed systematically instead of silently slowing down development.
Maintain a visible debt list. If it’s invisible, it will grow silently.
Communicate trade-offs openly
Every decision in a startup involves trade-offs: speed vs. quality, features vs. maintainability.
By discussing these trade-offs openly, the team understands why shortcuts are taken and what the long-term consequences might be, preventing surprises and frustration later.
When choosing speed over quality, say it clearly. Hidden trade-offs cause resentment later.
Optimize for sustainability, not heroics
Late nights, rushed fixes, and “heroic” efforts might save the day once, but they’re not a process.
Focus on building a sustainable pace, predictable delivery, and maintainable code. Consistent, steady progress beats short-term heroics that burn out the team and introduce hidden issues.
Late nights and emergency fixes are not a process.
They’re symptoms. Healthy teams ship consistently, not dramatically.
Conclusion
When people search for “Startup Software Development Process Explained,” they expect a framework.
But in real projects, the process doesn’t break because the framework was wrong.
It breaks because execution discipline collapses after MVP.
The fix is not more tools.
Not more ceremonies.
Not more developers.
It’s:
- Clear ownership
- Controlled scope
- Continuous refactoring
- Replaceable architecture
- Measured outcomes
If your development slowed down after launch, the problem isn’t growth.
It’s accumulated shortcuts meeting real-world pressure.
Fix that layer first.
FAQs
It can help with structure, but strict Scrum often adds overhead for teams under 10 people.
Because early shortcuts become long-term constraints and real user complexity exposes fragile architecture.
By refactoring continuously and limiting scope creep during execution cycles.
Sometimes partially, but full rewrites are risky. Incremental improvement works better.
Structured enough to protect execution, but flexible enough to adapt product direction.
About the Author
Paras Dabhi
VerifiedFull-Stack Developer (Python/Django, React, Node.js) · Stellar Code System
Hi, I’m Paras Dabhi. I build scalable web applications and SaaS products with Django REST, React/Next.js, and Node.js. I focus on clean architecture, performance, and production-ready delivery with modern UI/UX.

Paras Dabhi
Stellar Code System
Building scalable CRM & SaaS products
Clean architecture · Performance · UI/UX